เส้นโค้งปกติ (Normal Distribution) ไม่ได้พบในทุกตัวแปรในโลก เรื่องปกติที่นักวิเคราะห์ควรเข้าใจ
5 เมษายน 2566 - เวลาอ่าน 2 นาที
หากคุณได้เรียนวิชาสถิติมา คุณอาจเคยได้ยินว่า ตัวแปรส่วนใหญ่ในโลก ล้วนเป็นโค้งปกติ (Normal distribution)
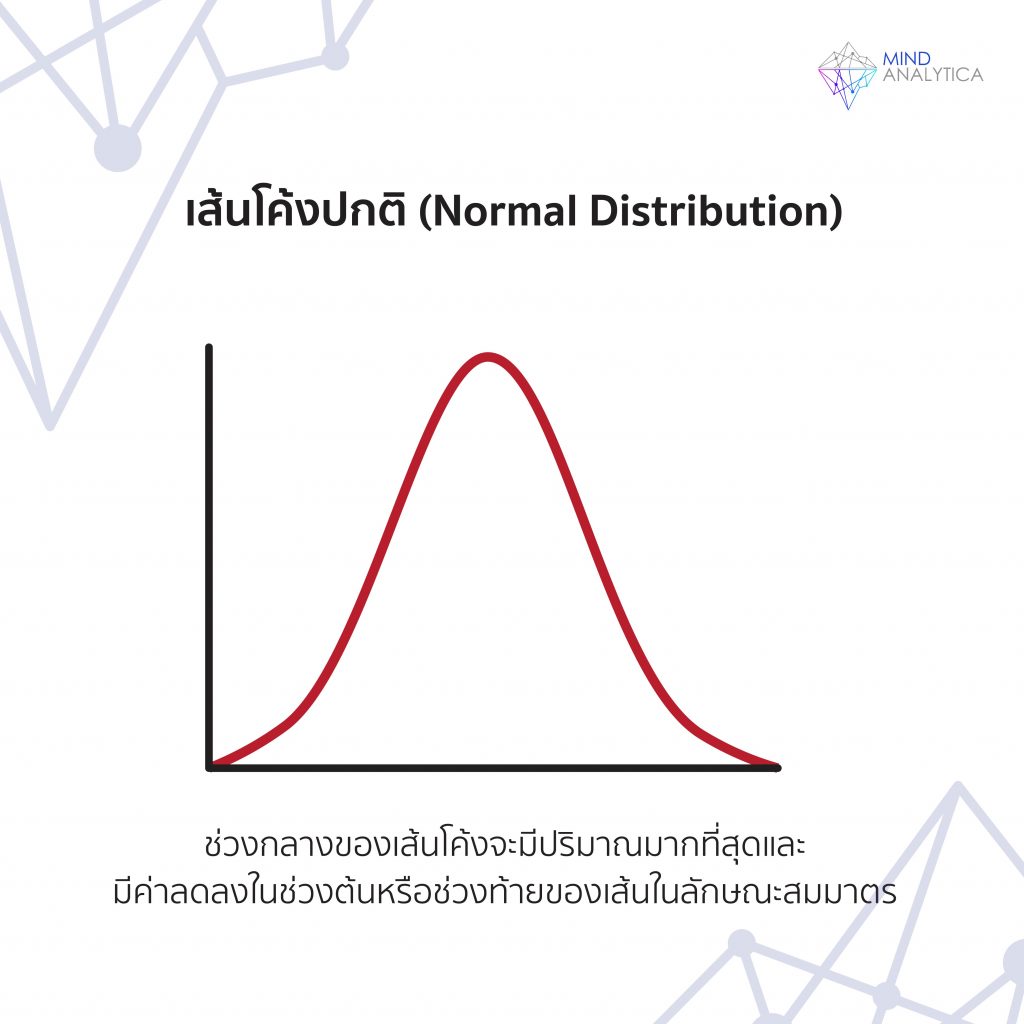

เพื่อให้การอธิบายชัดเจน ขออนุญาตยกตัวอย่างเรื่องความสูงของมนุษย์ มนุษย์ส่วนใหญ่ก็จะมีความสูงระดับปานกลาง (เช่น 160 -175 เซนติเมตร) แต่จะมีคนสูงมาก (สูงกว่า 175 เซนติเมตร) จำนวนน้อยกว่าคนสูงระดับปานกลาง และมีคนสูงน้อย (น้อยกว่า 160 เซนติเมตร) จำนวนน้อยกว่าคนสูงระดับปานกลาง หากนำคะแนนของคนมาสร้างกราฟ โดยนำจำนวนคนที่เจอในแต่ละช่วงความสูง มาเป็นระดับความสูงของกราฟ (แกน Y) และนำความสูงของคนมาเรียงลำดับจากน้อยไปหามาก (แกน X) จะพบว่ากราฟออกมาจะคล้ายๆ รูประฆังคว่ำ (The bell curve) นักสถิติจะเรียกว่าการกระจายของความสูง อยู่ในรูปโค้งปกติ แต่ในโลกแห่งความเป็นจริง ตัวแปรจำนวนมากก็ไม่ได้เป็นโค้งปกติ
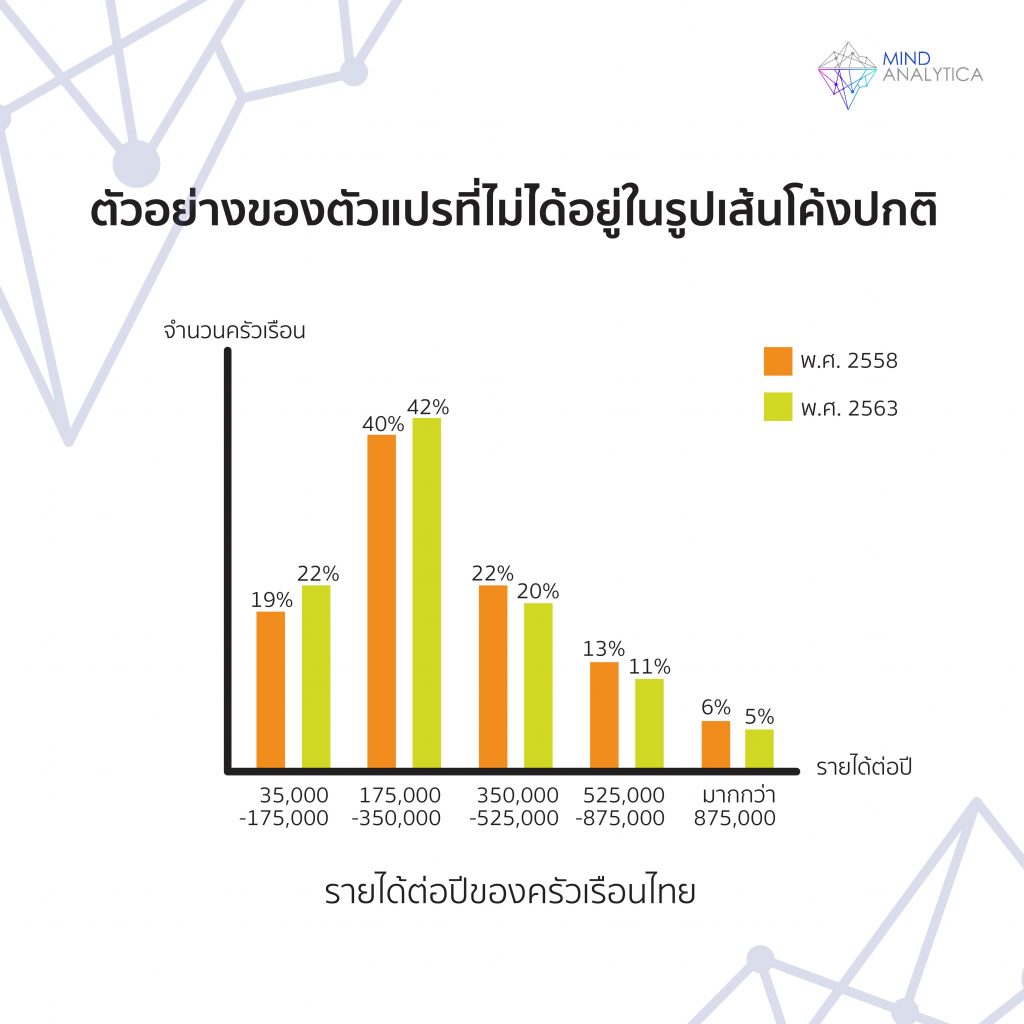
ตัวอย่างง่ายๆ ของตัวแปรที่ไม่ได้มีการกระจายเป็นโค้งปกติ คือ รายได้ของครัวเรือนไทย จะเห็นว่าครัวเรือนส่วนใหญ่ มีรายได้อยู่ที่ 175,000-350,000 บาทต่อปี (15,000 - 30,000 บาทต่อเดือน) แต่กลุ่มคนที่รายได้ต่ำกว่า 175,000 บาท และสูงกว่า 350,000 บาทไม่เท่ากัน ครัวเรือนส่วนที่มีรายได้มากกว่า 350,000 บาทมีมากกว่า กล่าวคือ การกระจายไปทั้งสองข้างไม่เท่ากัน มีครัวเรือนที่รายได้สูงมากๆ อยู่ รูปร่างไม่ได้เป็นระฆังคว่ำอย่างที่แสดงไว้ด้านบน อีกตัวอย่างหนึ่ง เช่น ตัวแปรประเภทจัดกลุ่ม เช่น เพศชายหรือหญิง ชอบกินก๋วยเตี๋ยวหรือไม่ชอบ ฯลฯ ตัวแปรเหล่านี้ จะมีค่าที่เป็นไปได้จำกัด มีเพียงสองค่า ถ้านำมาสร้างเป็นกราฟ จะไม่มีวันได้กราฟรูปโค้งปกติแน่นอน

ทำไมนักสถิติถึงใช้โค้งปกติจำนวนมาก ทั้งที่ตัวแปรจำนวนมากในโลกไม่ได้เป็นโค้งปกติ เมื่อเรียนสถิติขั้นสูง ก็จะยิ่งรู้สึกย้อนแย้ง เพราะนักสถิติมักจะกล่าวเงื่อนไขว่าการกระจายของคะแนนเป็นโค้งปกติ เมื่อการกระจายของคะแนนในประชากระเป็นโค้งปกติแล้ว ถึงจะสามารถใช้สถิติขั้นสูงรูปแบบต่างๆ ได้ สาเหตุมาจากสองปัจจัย ประการแรกคือ ทฤษฎีแนวโน้มเข้าสู่ศูนย์กลาง (Central Limit Theorem) นักสถิติได้ทดสอบทางคณิตศาสตร์แล้ว พบว่าหากสุ่มคนออกมาจำนวนหนึ่ง แล้วนำมาหารค่าเฉลี่ย (หรือผลรวม) พบว่ารูปการกระจายของค่าเฉลี่ย (หรือผลรวม) จะเป็นโค้งปกติ ยิ่งจำนวนคนที่สุ่มมาหาค่าเฉลี่ยยิ่งสูง (เช่น มากกว่า 30 คน) จะยิ่งทำให้การกระจายของค่าเฉลี่ยที่ได้คล้ายกับโค้งปกติมากขึ้น ผู้อ่านสามารถลองเล่น application ได้จาก link นี้ เพื่อความเข้าใจในทฤษฎีแนวโน้มสู่ศูนย์กลางมากขึ้น https://onlinestatbook.com/stat_sim/sampling_dist/
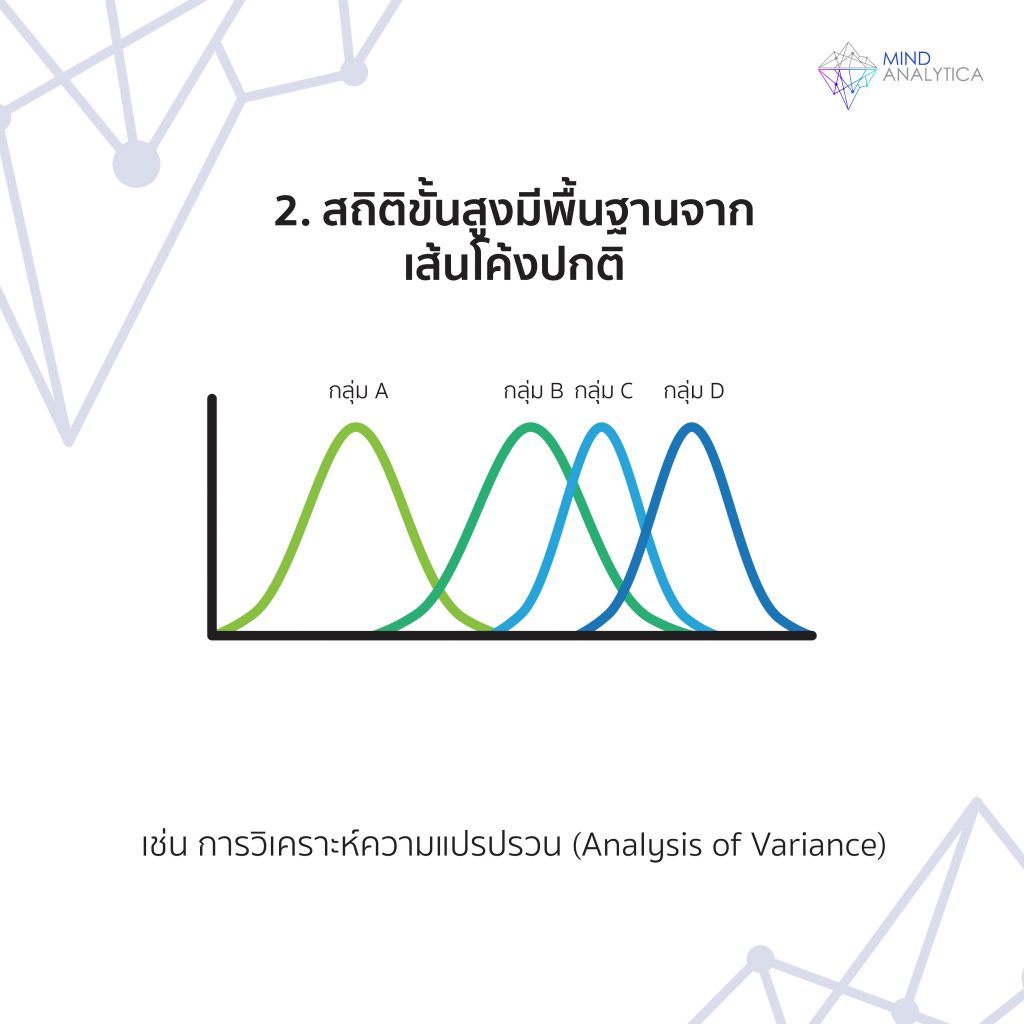
ประการที่สอง คือ เพื่อให้การพัฒนาสถิติขั้นสูงดำเนินไปต่อได้ นักสถิติจึงเหมาไปก่อน ว่าการกระจายของประชากรที่กลุ่มตัวอย่างสุ่มออกมาเป็นเป็นโค้งปกติ เมื่อเหมาไปแล้ว ทำให้การสร้างสูตรทางคณิตศาสตร์ทำไปได้ง่ายดายขึ้น เช่น การวิเคราะห์ความแปรปรวน (Analysis of variance) ที่นักสถิติจะเหมารวมไปก่อนว่าการกระจายของคะแนนภายในแต่ละกลุ่มในประชากร มีการกระจายเป็นโค้งปกติ เพื่อให้ได้ค่าระดับนัยสำคัญ (ที่มาจากการกระจายแบบ F) แล้วนำไปทดสอบว่าค่าเฉลี่ยของประชากรแต่ละกลุ่มแตกต่างกันระหว่างกลุ่มหรือไม่
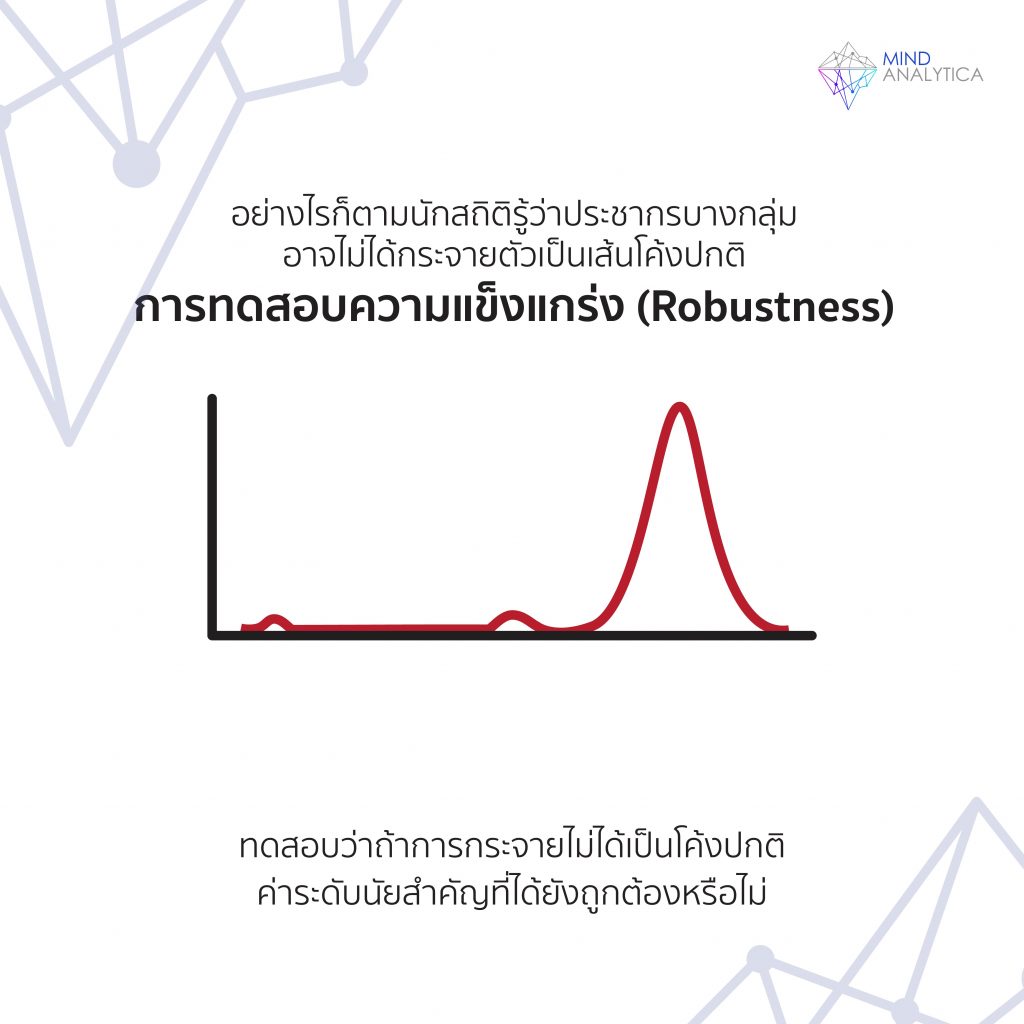
อย่างไรก็ตาม เมื่อเหมารวมไปแล้ว นักสถิติก็ตระหนักดีว่าประชากรของแต่ละกลุ่มอาจไม่มีการกระจายเป็นโค้งปกติเสมอไป เขาจึงทดสอบว่าถ้าการกระจายไม่ได้เป็นโค้งปกติ ค่าระดับนัยสำคัญที่ได้ยังถูกต้องหรือไม่ เรียกการทดสอบนี้ว่าการทดสอบความแข็งแกร่งของการละเมิดการเหมารวมดังกล่าว (Robustness) สถิติแต่ละตัวก็มีความคงทนต่อการเหมารวมแบบนี้แตกต่างกัน การวิเคราะห์ความแปรปรวนที่ยกเป็นตัวอย่างข้างต้นคงทนมากต่อการละเมิดการเหมารวมที่ประชากรของแต่ละกลุ่มเป็นโค้งปกติ
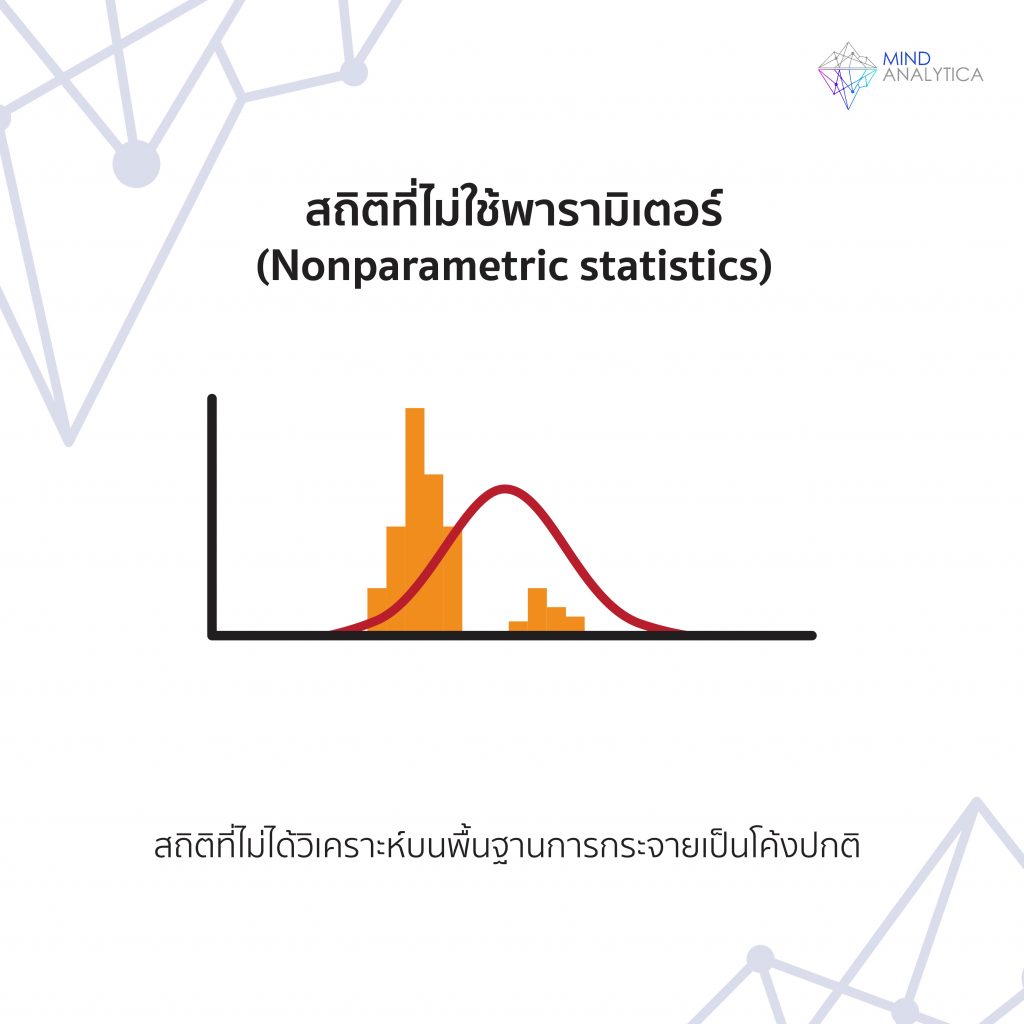
อย่างไรก็ตาม นักวิจัยบางคนได้พัฒนาสถิติที่ไม่ได้เหมารวมว่าประชากรมีการกระจายเป็นโค้งปกติ สถิติกลุ่มนี้จะเรียกว่าสถิติที่ไม่ใช้พารามิเตอร์ (Nonparametric statistics)

ดังนั้น โค้งปกติเป็นเพียงเครื่องมือที่นักสถิติใช้ เพื่อให้การคิดสูตร คิดสถิติทำได้ง่ายขึ้น แต่นักสถิติไม่ได้เหมารวมไปว่าทุกอย่างต้องเป็นโค้งปกติ นักสถิติรู้และเข้าใจว่าตัวแปรบางตัวอาจไม่ได้มีการกระจายเป็นโค้งปกติ และได้หาทางออกไว้แล้ว ดังนั้นนักวิเคราะห์ควรเข้าใจว่า สถิติแต่ละตัวมีข้อจำกัดอะไร ได้เหมารวมการกระจายประชากรเป็นโค้งปกติหรือไม่ และหากเหมา สถิติที่ใช้แข็งแกร่งต่อการละเมิดดังกล่าวมากน้อยเพียงใด นักวิเคราะห์ไม่จำเป็นต้องไปแปลงคะแนน เช่น ใส่ค่า log กับคะแนน ถ้าสถิติดังกล่าวแข็งแกร่งต่อการละเมิดการเหมาว่าประชากรเป็นโค้งปกติ การไปแปลงค่าอาจทำให้การตีความหมายข้อมูลยากมากขึ้นด้วยซ้ำ
ผู้เขียน



